当你 INSERT 一行记录到 PostgreSQL 时,数据并不会立即写到磁盘文件中,而是会先写入 Shared Buffer,过一段时间才会落盘。同样的,当你 SELECT 一些数据时,也不会每次都会实时从磁盘文件中读取,很大概率会从 Shared Buffer 直接获取。那么 Shared Buffer 内部的结构是怎样的呢?本文将会介绍 Shared Buffer 的工作原理,逐步揭开其神秘面纱。
整体架构
Shared Buffer 内部其实分为了三层,从上到下依次是 Buffer Table、Buffer Descriptor、Buffer Pool。Buffer Table 是一个 Hash 表,Buffer Descriptor、Buffer Pool 是数组,二者等长。
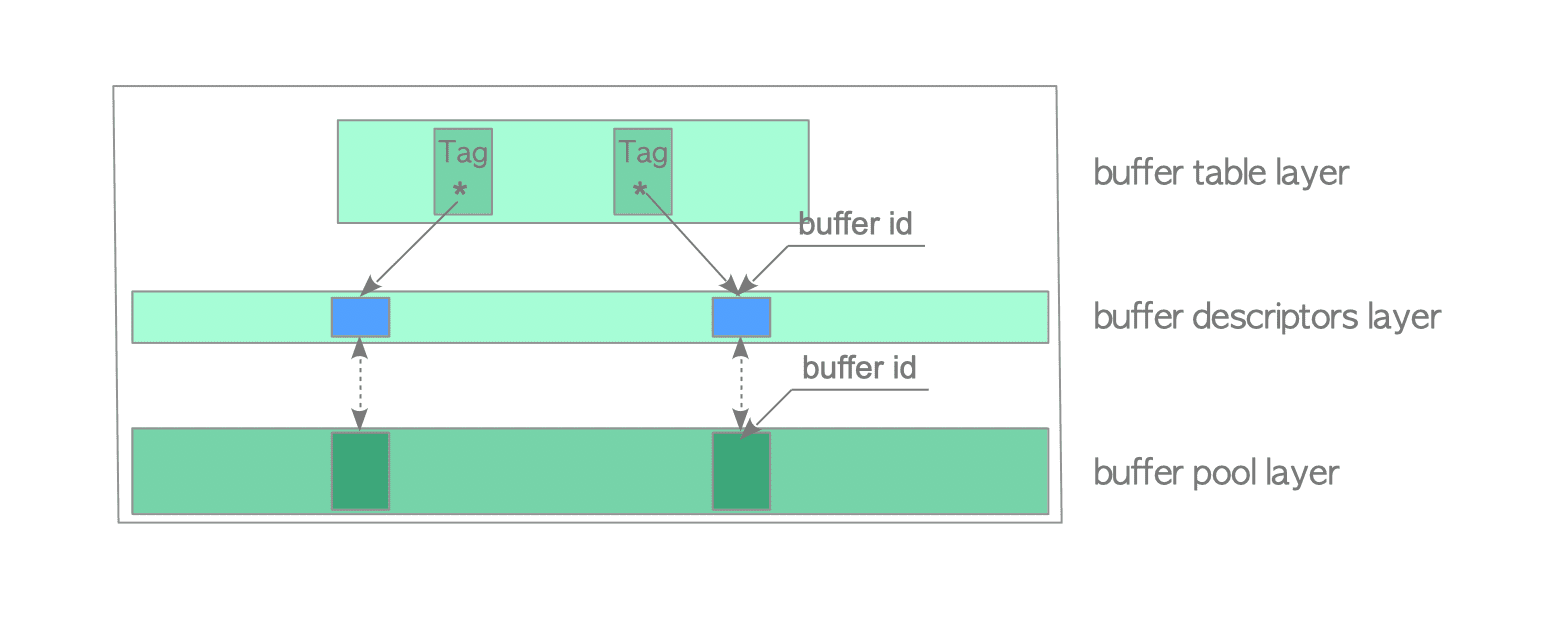
Buffer Pool
在物理上,PostgreSQL 的 Table 或者 Index 的存储最小单位是 Block,一个 Block 一般是 8KB。Buffer Pool 是存储 Block 的一维数组,数组中的每个 slot 大小和 Block 等长,不存储其它额外数据。
Buffer Descriptor
Buffer Descriptor 和 Buffer Pool 这两个数组中的数据一一对应,Buffer Pool 只存储 Block,而 Buffer Descriptor 存储的是对应的 Block 的元信息,包括:
- buf_id buffer id 就是 Block 在 Buffer Pool 中的 Index
- tag 也就是 Buffer Tag,我们稍后介绍 Buffer Table时再详细介绍
- usage_count 此 Block 在加载到 Buffer Pool 后,被使用的次数
- refcount 也可以称为 pin count 也就是当前有多少 Postgres 进程正在使用它
- flags 标记 block 状态
- dirty bit 是否 dirty,也就是内容是否被修改
- valid bit 是否 valid,也就是能不能正常读写
- freeNext 下一个空闲的 descriptor,用来形成 freelist,标记空闲空间
// https://github.com/postgres/postgres/blob/REL_13_4/src/include/storage/buf_internals.h#L177
/*
* Buffer state is a single 32-bit variable where following data is combined.
*
* - 18 bits refcount
* - 4 bits usage count
* - 10 bits of flags
*
* Combining these values allows to perform some operations without locking
* the buffer header, by modifying them together with a CAS loop.
*
* The definition of buffer state components is below.
*/
#define BUF_REFCOUNT_ONE 1
#define BUF_REFCOUNT_MASK ((1U << 18) - 1)
#define BUF_USAGECOUNT_MASK 0x003C0000U
#define BUF_USAGECOUNT_ONE (1U << 18)
#define BUF_USAGECOUNT_SHIFT 18
#define BUF_FLAG_MASK 0xFFC00000U
/* Get refcount and usagecount from buffer state */
#define BUF_STATE_GET_REFCOUNT(state) ((state) & BUF_REFCOUNT_MASK)
#define BUF_STATE_GET_USAGECOUNT(state) (((state) & BUF_USAGECOUNT_MASK) >> BUF_USAGECOUNT_SHIFT)
/*
* Flags for buffer descriptors
*
* Note: BM_TAG_VALID essentially means that there is a buffer hashtable
* entry associated with the buffer's tag.
*/
#define BM_LOCKED (1U << 22) /* buffer header is locked */
#define BM_DIRTY (1U << 23) /* data needs writing */
#define BM_VALID (1U << 24) /* data is valid */
#define BM_TAG_VALID (1U << 25) /* tag is assigned */
#define BM_IO_IN_PROGRESS (1U << 26) /* read or write in progress */
#define BM_IO_ERROR (1U << 27) /* previous I/O failed */
#define BM_JUST_DIRTIED (1U << 28) /* dirtied since write started */
#define BM_PIN_COUNT_WAITER (1U << 29) /* have waiter for sole pin */
#define BM_CHECKPOINT_NEEDED (1U << 30) /* must write for checkpoint */
#define BM_PERMANENT (1U << 31) /* permanent buffer (not unlogged,
* or init fork) */
/*
* The maximum allowed value of usage_count represents a tradeoff between
* accuracy and speed of the clock-sweep buffer management algorithm. A
* large value (comparable to NBuffers) would approximate LRU semantics.
* But it can take as many as BM_MAX_USAGE_COUNT+1 complete cycles of
* clock sweeps to find a free buffer, so in practice we don't want the
* value to be very large.
*/
#define BM_MAX_USAGE_COUNT 5
/*
* BufferDesc -- shared descriptor/state data for a single shared buffer.
*
* Note: Buffer header lock (BM_LOCKED flag) must be held to examine or change
* the tag, state or wait_backend_pid fields. In general, buffer header lock
* is a spinlock which is combined with flags, refcount and usagecount into
* single atomic variable. This layout allow us to do some operations in a
* single atomic operation, without actually acquiring and releasing spinlock;
* for instance, increase or decrease refcount. buf_id field never changes
* after initialization, so does not need locking. freeNext is protected by
* the buffer_strategy_lock not buffer header lock. The LWLock can take care
* of itself. The buffer header lock is *not* used to control access to the
* data in the buffer!
*
* It's assumed that nobody changes the state field while buffer header lock
* is held. Thus buffer header lock holder can do complex updates of the
* state variable in single write, simultaneously with lock release (cleaning
* BM_LOCKED flag). On the other hand, updating of state without holding
* buffer header lock is restricted to CAS, which insure that BM_LOCKED flag
* is not set. Atomic increment/decrement, OR/AND etc. are not allowed.
*
* An exception is that if we have the buffer pinned, its tag can't change
* underneath us, so we can examine the tag without locking the buffer header.
* Also, in places we do one-time reads of the flags without bothering to
* lock the buffer header; this is generally for situations where we don't
* expect the flag bit being tested to be changing.
*
* We can't physically remove items from a disk page if another backend has
* the buffer pinned. Hence, a backend may need to wait for all other pins
* to go away. This is signaled by storing its own PID into
* wait_backend_pid and setting flag bit BM_PIN_COUNT_WAITER. At present,
* there can be only one such waiter per buffer.
*
* We use this same struct for local buffer headers, but the locks are not
* used and not all of the flag bits are useful either. To avoid unnecessary
* overhead, manipulations of the state field should be done without actual
* atomic operations (i.e. only pg_atomic_read_u32() and
* pg_atomic_unlocked_write_u32()).
*
* Be careful to avoid increasing the size of the struct when adding or
* reordering members. Keeping it below 64 bytes (the most common CPU
* cache line size) is fairly important for performance.
*/
typedef struct BufferDesc
{
BufferTag tag; /* ID of page contained in buffer */
int buf_id; /* buffer's index number (from 0) */
/* state of the tag, containing flags, refcount and usagecount */
pg_atomic_uint32 state;
int wait_backend_pid; /* backend PID of pin-count waiter */
int freeNext; /* link in freelist chain */
LWLock content_lock; /* to lock access to buffer contents */
} BufferDesc;
Buffer Table
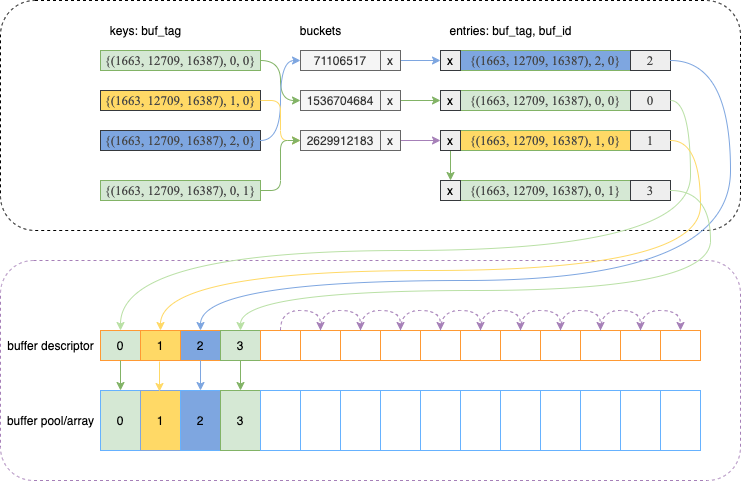
Buffer Table 是个 hash table,存储的是 Buffer Tag 到 Buffer ID 的映射。Buffer Tag 其实就是一种逻辑上唯一标识某个 Block 的方式。
Buferr Tag
Buffer Tag 结构为:
Tablespace, Database, Table, ForkNumber, BlockNumber
5个字段都是整数,其中Tablespace, Database, Table 是 OID ,ForkNumber 是 enum(区分数据文件、freespace、visibile map),BlockNumber是 uint32。
// https://github.com/postgres/postgres/blob/REL_13_4/src/include/storage/buf_internals.h#L90
/*
* Buffer tag identifies which disk block the buffer contains.
*
* Note: the BufferTag data must be sufficient to determine where to write the
* block, without reference to pg_class or pg_tablespace entries. It's
* possible that the backend flushing the buffer doesn't even believe the
* relation is visible yet (its xact may have started before the xact that
* created the rel). The storage manager must be able to cope anyway.
*
* Note: if there's any pad bytes in the struct, INIT_BUFFERTAG will have
* to be fixed to zero them, since this struct is used as a hash key.
*/
typedef struct buftag
{
RelFileNode rnode; /* physical relation identifier */
ForkNumber forkNum;
BlockNumber blockNum; /* blknum relative to begin of reln */
} BufferTag;
// https://github.com/postgres/postgres/blob/REL_13_4/src/include/storage/relfilenode.h#L57
/*
* RelFileNode must provide all that we need to know to physically access
* a relation, with the exception of the backend ID, which can be provided
* separately. Note, however, that a "physical" relation is comprised of
* multiple files on the filesystem, as each fork is stored as a separate
* file, and each fork can be divided into multiple segments. See md.c.
*
* spcNode identifies the tablespace of the relation. It corresponds to
* pg_tablespace.oid.
*
* dbNode identifies the database of the relation. It is zero for
* "shared" relations (those common to all databases of a cluster).
* Nonzero dbNode values correspond to pg_database.oid.
*
* relNode identifies the specific relation. relNode corresponds to
* pg_class.relfilenode (NOT pg_class.oid, because we need to be able
* to assign new physical files to relations in some situations).
* Notice that relNode is only unique within a database in a particular
* tablespace.
*
* Note: spcNode must be GLOBALTABLESPACE_OID if and only if dbNode is
* zero. We support shared relations only in the "global" tablespace.
*
* Note: in pg_class we allow reltablespace == 0 to denote that the
* relation is stored in its database's "default" tablespace (as
* identified by pg_database.dattablespace). However this shorthand
* is NOT allowed in RelFileNode structs --- the real tablespace ID
* must be supplied when setting spcNode.
*
* Note: in pg_class, relfilenode can be zero to denote that the relation
* is a "mapped" relation, whose current true filenode number is available
* from relmapper.c. Again, this case is NOT allowed in RelFileNodes.
*
* Note: various places use RelFileNode in hashtable keys. Therefore,
* there *must not* be any unused padding bytes in this struct. That
* should be safe as long as all the fields are of type Oid.
*/
typedef struct RelFileNode
{
Oid spcNode; /* tablespace */
Oid dbNode; /* database */
Oid relNode; /* relation */
} RelFileNode;
// https://github.com/postgres/postgres/blob/REL_13_4/src/include/common/relpath.h#L40
/*
* Stuff for fork names.
*
* The physical storage of a relation consists of one or more forks.
* The main fork is always created, but in addition to that there can be
* additional forks for storing various metadata. ForkNumber is used when
* we need to refer to a specific fork in a relation.
*/
typedef enum ForkNumber
{
InvalidForkNumber = -1,
MAIN_FORKNUM = 0,
FSM_FORKNUM,
VISIBILITYMAP_FORKNUM,
INIT_FORKNUM
/*
* NOTE: if you add a new fork, change MAX_FORKNUM and possibly
* FORKNAMECHARS below, and update the forkNames array in
* src/common/relpath.c
*/
} ForkNumber;
// https://github.com/postgres/postgres/blob/REL_13_4/src/include/storage/block.h#L31
/*
* BlockNumber:
*
* each data file (heap or index) is divided into postgres disk blocks
* (which may be thought of as the unit of i/o -- a postgres buffer
* contains exactly one disk block). the blocks are numbered
* sequentially, 0 to 0xFFFFFFFE.
*
* InvalidBlockNumber is the same thing as P_NEW in bufmgr.h.
*
* the access methods, the buffer manager and the storage manager are
* more or less the only pieces of code that should be accessing disk
* blocks directly.
*/
typedef uint32 BlockNumber;
增删改查
SQL 中 INSERT DELETE UPDATE SELECT 都会与 Shared Buffer 交互数据:
- INSERT: 把新数据写到 Shared Buffer, buffer descriptor 被标记为 dirty
- DELETE: 先查询出要删除的数据,加载到 Shared Buffer,修改 row header,标记删除,buffer descriptor 被标记为 dirty
- UPDATE:先把旧数据标记删除,与 DELETE 流程一样,然后把旧数据 COPY 一份到 Shared Buffer,修改需要修改的内容,buffer descriptor 被标记为 dirty
- SELECT:把数据从磁盘加载到 Shared Buffer
被标记为 dirty 的 block,pg_bgwriter 之后会将其落盘。
(insert 新数据的时候,是怎么知道 block number的呢?pg_freespacemap 记录了block 的空闲信息,要么新增 block,要么从旧block中找一个有空闲的)
上述增删改查操作,对于 Shared Buffer而言,分为两类:
- . 1. 写新数据到 Shared Buffer
- . 2. 从 Shared Buffer 查询数据:
- . 2.1 数据已经在 Shared Buffer
- . 2.2 数据不在 Shared Buffer
先不考虑Shared Buffer 已经满了的情况。
对于写新数据,很简单:
- 找一个空闲的 Buffer Descriptor,记录其 Buffer ID,更新其 flag usage_count usage_count 等数据
- 往对应的 Buffer Pool 中写 Block 数据
- 往Buffer Table里面写入 Buffer Tag -> Bufer ID 的映射
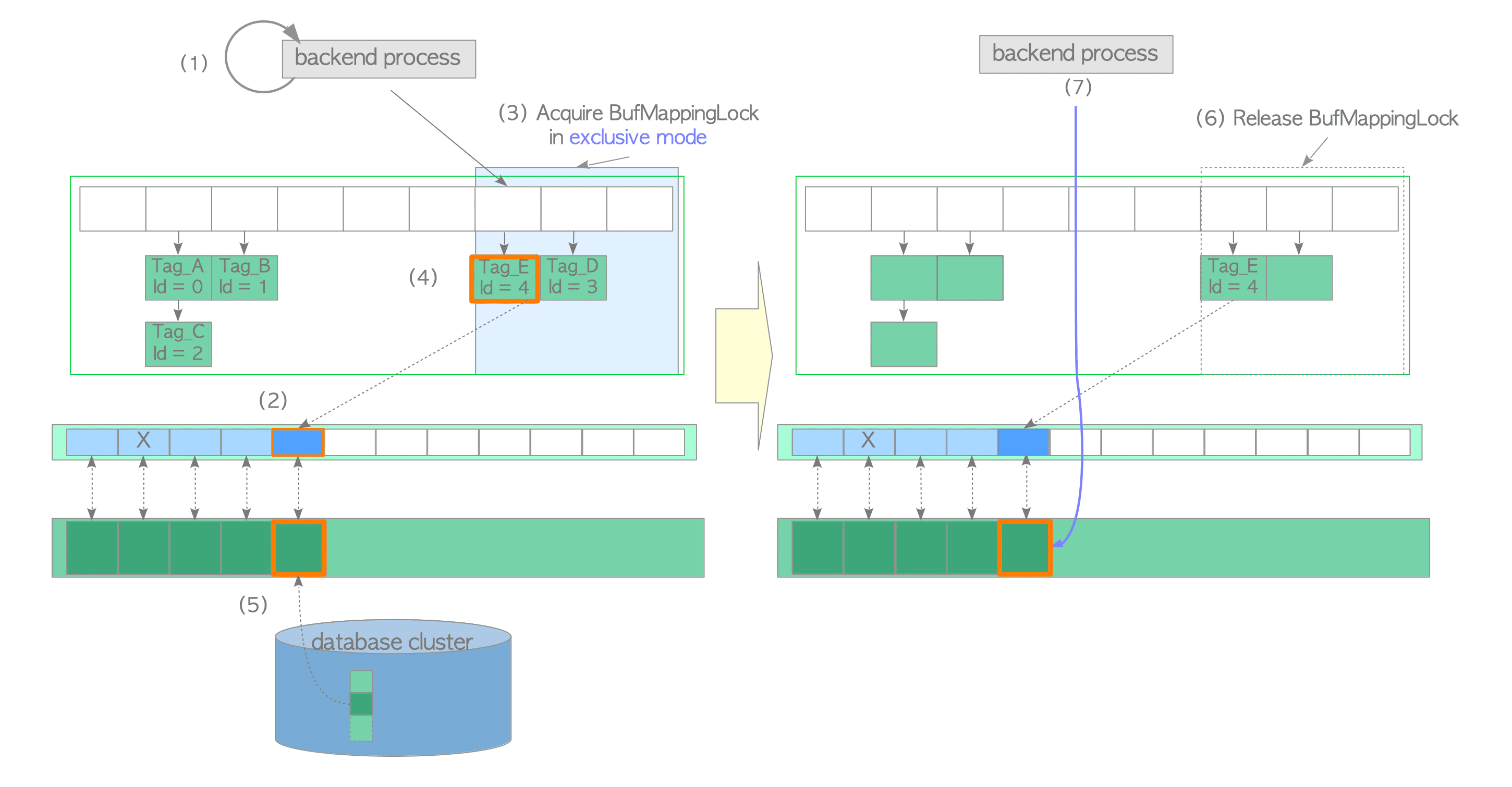
对于读取数据:
- 先通过 Buffer Table 找到其对应的 Buffer ID,如果能找到,则更新Buffer Descriptor 相关信息,直接从 Buffer Pool 中取数据
- 找不到 Buffer ID 的话,则需要找一个空闲的 Buffer Descriptor,从磁盘加载对应的 Block 到 Buffer Pool,更新Buffer Descriptor 相关信息,返回数据。
下图是从磁盘读数据,写到 Shared Buffer 的示意图,来自这篇文章。(该文章中还有很多种其它情况的示意图。)
驱逐算法
之前假设了 Shared Buffer 还有空余空间,处理起来比较简单。如果 Shared Buffer 满了呢?满了之后就只能从中删除一些数据了,比如使用 Least Recently Used 算法删掉不常用的。
PostgreSQL 没有采用 LRU算法,可能是需要记录一些时间啊什么的额外信息,比较麻烦。PostgreSQL 使用的是 Clock Sweep 算法。首先,我们要明确,只有 unpinned 的 Block 才需要被清除,也就是当前没有被使用的,也就是 refcount = 0。Clock Sweep 算法很容易理解,就是把 Buffer Descriptor 看成是一个环,然后开始遍历,遍历的时候发现 refcount = 0就把它清理掉,如果不为0,则refcount--。即便是转了1圈都没有找到refcount = 0的,由于refcount--了,第2圈、第3圈总会找到的。
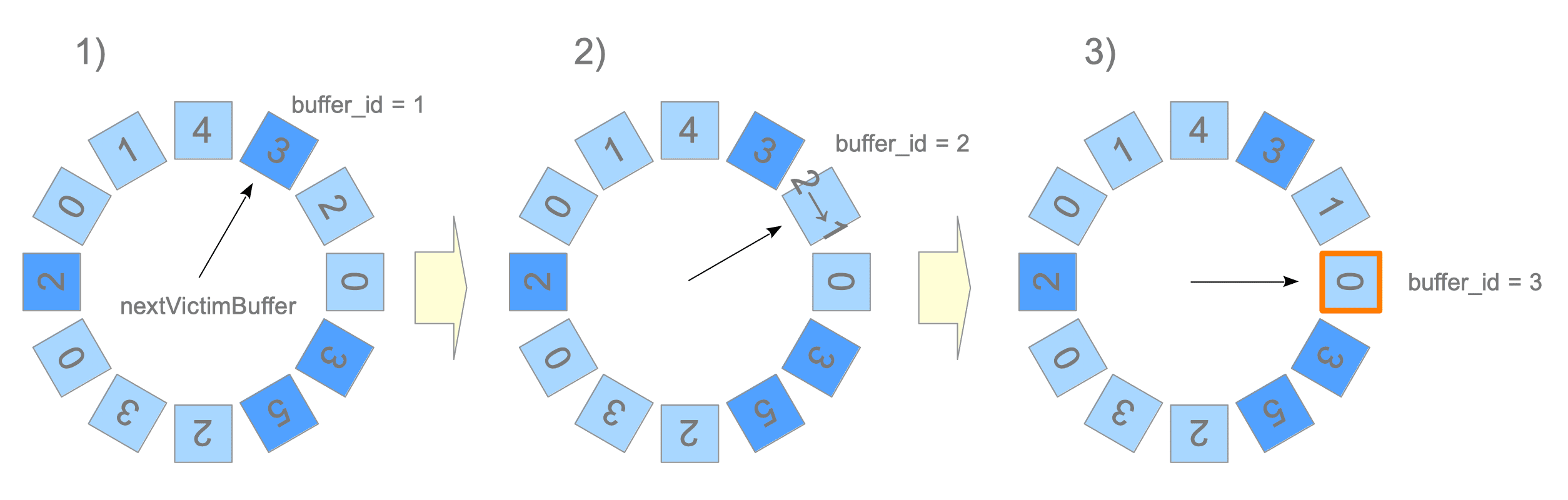
找到之后怎么进行清除呢?其实就是把旧Block flush 到磁盘,新Block写到对应的 Buffer Pool Entry 中,然后更新一下 Buffer Descriptor 中的计数信息,再删掉 Buffer Table 中的旧映射,写入新映射即可。
Ring Buffer
当读写大表时,为了避免Shared Buffer 被占满,PostgreSQL 使用一个临时的 Ring Buffer 区域来存放数据(src/backend/storage/buffer/README#L218)
- 顺序扫描: 最大 256KB
- VACUUM: 最大 256KB
- Bulk Insert: 最大 16MB
Stats
Shared Buffer 大小要怎么设置呢?官方推荐是用机器内存的 25% (Ref)。可以通过SQL命令来查询当前设置的大小。
postgres=# show shared_buffers;
shared_buffers
----------------
128MB
(1 row)
postgres=#
怎么查询当前已经使用了多少 Shared Buffer 呢?可以通过 pg_buffercache 这个 extension 来查询。
Ring Buffer
Bulk Insert
下面我们来测试一下,写入1千多万数据,看 Shared Buffer 数据量有无明显变化。
postgres=# select count(*) from pg_buffercache where relfilenode is null;
count
-------
16281
(1 row)
postgres=# create table test as select generate_series(1,12345678);
SELECT 12345678
postgres=# select count(*) from pg_buffercache where relfilenode is null;
count
-------
14209
(1 row)
postgres=# SELECT count(distinct bufferid) FROM pg_buffercache WHERE relfilenode = pg_relation_filenode('test'::regclass);
count
-------
2048
(1 row)
postgres=# select 2048*8/1024;
?column?
----------
16
(1 row)
postgres=# SELECT pg_size_pretty( pg_total_relation_size('test') );
pg_size_pretty
----------------
427 MB
(1 row)
postgres=#
可以发现test表的大小为 427MB,确刚好只用了 16MB的 Shared Buffer。
Seq Scan
重启PostgreSQL,对test表进行全表扫描时,发现使用了 768KB的 Shared Buffer,虽然比官方声称的256KB少,但是也是远远小于表大小了。
postgres=# SELECT count(distinct bufferid) FROM pg_buffercache WHERE relfilenode = pg_relation_filenode('test'::regclass);
count
-------
0
(1 row)
postgres=# select count(*) from test;
count
----------
12345678
(1 row)
postgres=# SELECT count(distinct bufferid) * 8 FROM pg_buffercache WHERE relfilenode = pg_relation_filenode('test'::regclass);
?column?
----------
768
(1 row)
postgres=#
命中率
当我们对SQL Query进行调优时,Shared Buffer 命中率将会有很大的参考价值。pg_statio_user_tables 记录了某个表读取 Shared Buffer 的总数以及命中次数,由此可以计算出命中率:
heap_blks_hit / heap_blks_hit + heap_blks_read
(完)
References:
- The Internals of PostgreSQL: Chapter 8 Buffer Manager
- A Comprehensive Guide: PostgreSQL Shared Buffers
- Let's get back to basics - PostgreSQL Memory Components
- Inside PostgreSQL Shared Memory
- Inside the PostgreSQL Shared Buffer Cache
- WAL in PostgreSQL: 1. Buffer Cache
- The Amazing Buffer Tag in PostgreSQL
- pg_buffercache