在使用C语言编写程序时,往往会有动态分配内存的需求,比如动态分配数组。动态申请的内存必须是一块连续的地址空间,在不再需要这块内存时,又会对内存进行释放操作。
当进行多次申请、释放之后,地址空间中会出现许多大大小小的空闲块,这些空闲块可能无法满足新的内存申请,这样就导致空闲块“被浪费了”,从而降低了内存的使用率。
设计较差的分配器不仅仅会造成内存使用率较低的问题,也很有可能花费更多的时间来搜索空闲块,造成系统吞吐率变低。
总结而言,分配器的目的有以下两个:
- 最大化内存利用率。
- 最大化吞吐量。
当然,鱼与熊掌不可兼得,设计良好的分配器需要在这两者之中权衡。
严格来说,分配器必须在以下约束条件下工作:
- 处理任意的请求序列。可以处理任意组合的
分配与释放请求。例如不保证所有分配请求都有与之对应的释放请求。 - 立即响应请求。必须立即响应请求,不能为了提高速率排序或者缓冲请求。
- 只使用堆。分配器所使用的非临时的数据结构都必须保存在堆上。
- 对齐块。分配器必须对齐块,使之可以保存任意类型的数据对象。
- 不修改已分配的块。不能修改已分配块的内容,也不能移动以分配块。
1. 内存块结构
在考虑具体的实现方式之前,先来想想内存块的结构是怎样的。假如我们用libc中的malloc分配了一块大小为m字节的内存M,那么M在分配器中的实际大小与其有效载荷m相等吗?
假若M被释放了,分配器怎么知道这块内存是空闲的?以及这个空闲块的大小?
不考虑某个具体的实现方式,通用的做法是在有效载荷前加入一块头部。在头部记录该内存块的大小以及是否空闲。
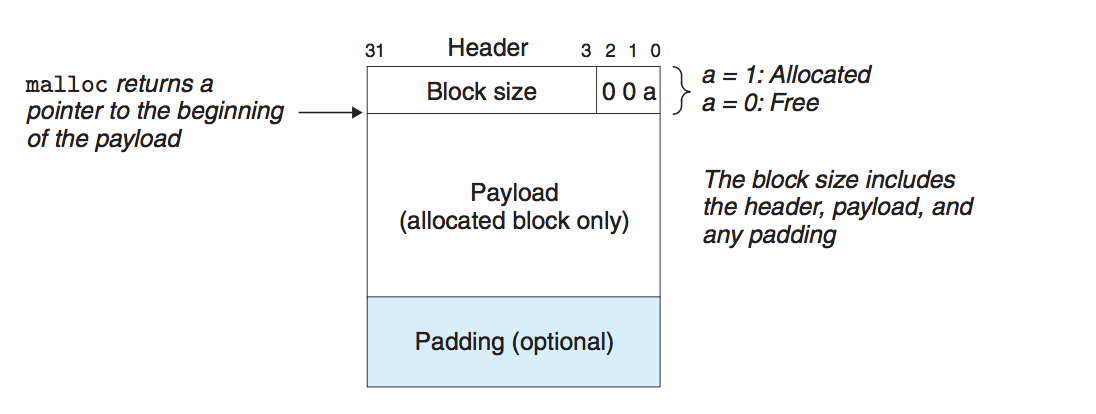
如上图所示,由于内存块都是经过对齐的,例如按8字节进行对齐,那么内存块的大小S肯定是8的倍数,因此,S的二进制表示的末三位一定是0。所以可以利用这后三位,用来存放一些额外的标识信息。上图中选择用最低位标识,1表示已分配,0表示未分配。
整个可以被分配器使用的堆内存空间,都以内存块为单位进行组织。也就是说堆被分成一块块连续的内存块,分配或释放都以内存块为单位进行操作。
2. 需要解决的问题
其实分配器整个是围绕空闲块来设计的,分配与释放都涉及到空闲块的管理,因此处理好空闲块是分配器的主要目标。以下是实现过程中的几个关键点:
-
碎片。在分配与释放的过程中,会产生两种碎片,导致内存使用率的降低:
- 内部碎片:已分配块与有效载荷之差。比如因对齐要求而产生。
- 外部碎片:指的是几个不连续的空闲块的大小之和可以满足新的分配请求,但是任一个单个空闲块无法满足新的请求。
-
空闲块组织。怎么记录空闲块?怎么组织空闲块才能在最快地响应分配请求呢?
-
空闲块选择。怎么最快地选择最合适的空闲块?
-
空闲块分割。怎么处理有效载荷之外的空闲部分?使之成为内部碎片还是变成新的较小的空闲块?
-
空闲块合并。如何处理刚刚被释放的空闲块?如何记录这个新增块?是否要、如何合并相邻的空闲块?
3. 空闲列表
为了解决空闲块的组织问题,可以使用空闲列表来记录所有的空闲块。也就是用链表将所有空闲块串起来。具体实现方式有隐式空闲列表与显式空闲列表两种。
3.1 隐式空闲列表
隐式空闲列表指的是不直接存放空闲链表的指针,而是利用空闲块头部的标志位来间接地将空闲块链接起来。
具体的实现方式简单而粗暴,就是当搜索空闲块时,从头遍历整个堆,遇到已分配块就跳过,直到找到空闲块。

如上图所示,图中的箭头并不是真实存在的指针,而是遍历内存块时跳过了已分配块。
3.1.1 内存块结构
为了在释放空闲块时合并相邻的空闲块,具体而言是为了与上一个内存块(地址较低)进行合并,必须要知道上一个内存块是否空闲,以及其大小。因此,仅仅使用头部标记是不够的,还需要在尾部加入与头部相同的内容。
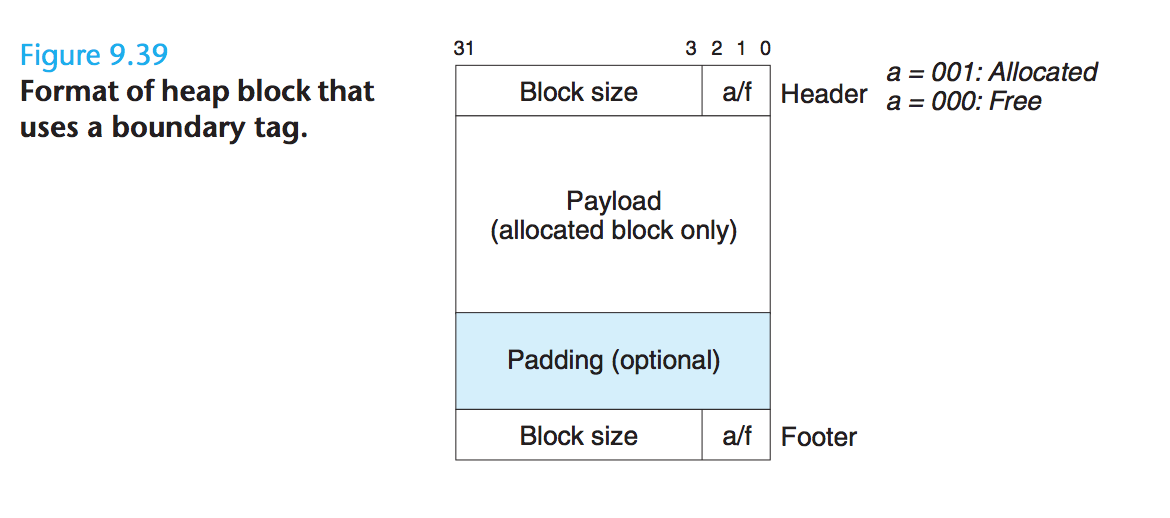
这样就可以通过移动当前块的指针到上一块的尾部,来判断其是否空闲,以及其大小,进而完成合并操作。
3.1.2 合并策略
在释放一个内存块时,可以根据与之相邻的两个内存块的使用情况来判断是否以及如何进行合并操作。
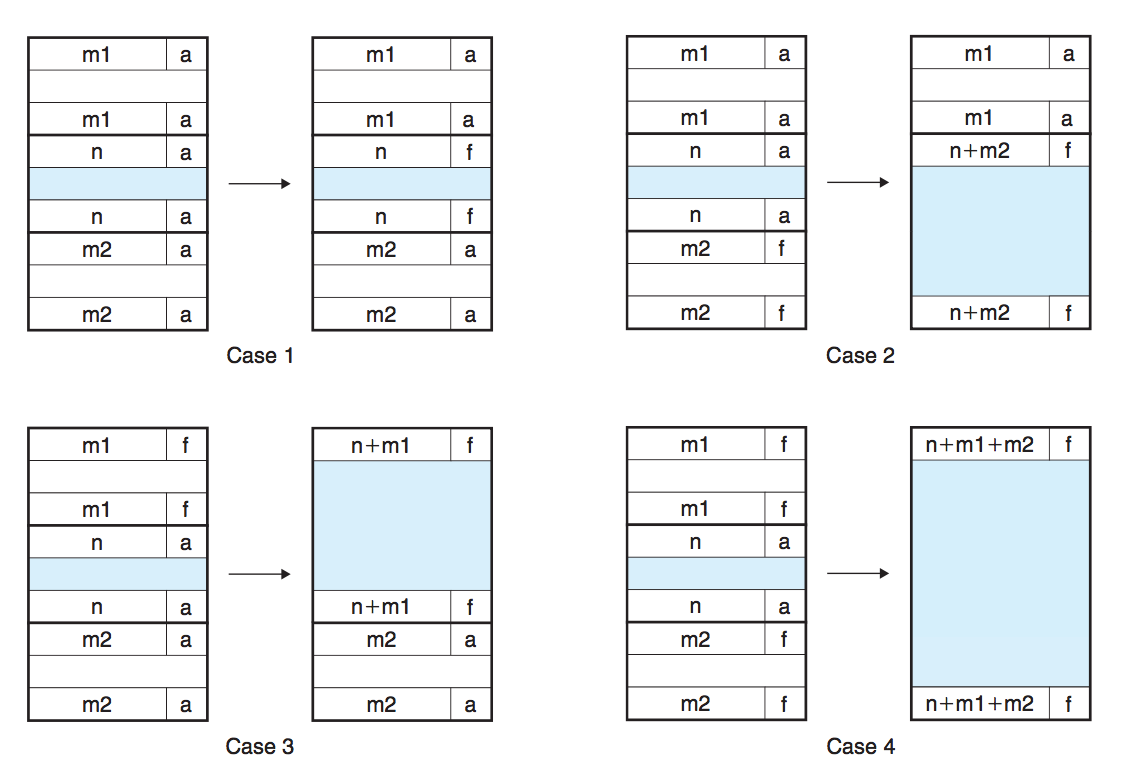
- 情况1,前后都是已分配块:把当前快标记为空闲即可。
- 情况2,前面已分配,后面是空闲块:更改当前快的首部,以及下一块的尾部。
- 情况3,前面是空闲块,后面是已分配块:更改上一块的首部,以及当前快的尾部。
- 情况4,前后都是空闲块:更改上一块的首部,以及下一块的尾部。
合并时只需要先确定新生成的空闲块的首部、尾部的位置以及块的大小,然后在首尾部更改大小,并标记为空闲即可。这样首尾之间的空间,就默认是这个新生成块的空闲空间了。
3.2 显式空闲列表
隐式空闲列表有一个弊端,就是每次搜索空闲块时都要搜索整个堆空间,这样会降低分配器的响应效率。因此,可以显式地记录空闲的地址,直接避开已分配块,加快搜索速度。
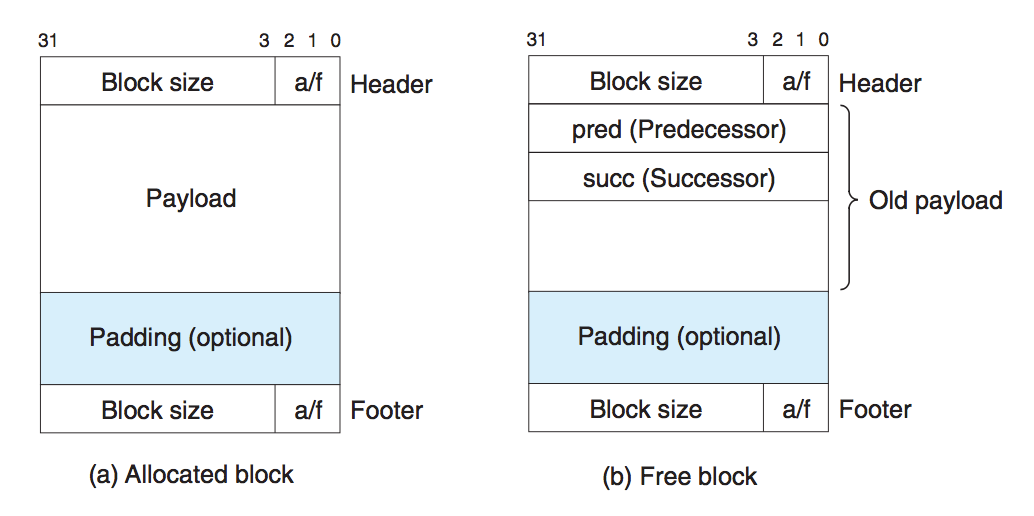
如上图,对于已分配块,其结构不变。对于空闲块,使用双向链表记录之,因此要记录两个指针。搜索时直接通过记录的指针来直接遍历空闲列表。为什么要使用双向链表呢?因为在进行合并操作时,会从空闲链表中删除旧的空闲块,这样就需要双向链表了。
新增一个空闲块时,可以按FIFO的原则按顺序链接空闲块,也可以按照地址高低对空闲块进行排序。合并时对链表的操作如下:
- 情况1,前后都是已分配块:把当前块插入链表,记录前后指针。
- 情况2,前面已分配,后面是空闲块:把当前块插入链表,记录前后指针,把下一块从空闲链表中删除。
- 情况3,前面是空闲块,后面是已分配块:链表无需修改。
- 情况4,前后都是空闲块:把下一块从空闲链表中删除。
4. 匹配方式
上节介绍了空闲块的组织方式,当申请一块内存时,还需要从空闲列表中找到合适的块用来分配。有以下几种方法:
-
首次匹配。从空闲链表头开始搜索,直到遇到大小合适的空闲块。
-
下次匹配。从上一次找到的空闲块处开始搜索。
-
最佳匹配。搜索整个空闲列表,选其中大小最合适的块。
5. 分离式空闲列表
上一节介绍的是使用单一的链表来记录空闲块,还有一种方式是按照块大小来维护多个空闲列表。每个空闲列表对应的是一个大小类。
可以根据2的幂来划分大小类:
{1}, {2}, {3 ~ 4}, {5 ~ 8}, {9 ~ 16}, ···, {1025 ~ 2048}, ···
或者是将小的块派分到他们自己的大小类中,大的块按照2的幂来划分:
{1}, {2}, {3}, {4}, {5}, ···, {1024}, {1025 ~ 2048}, {2049 ~ 4096} ···
分配器需要维护一个数组,记录各大小类对应的链表的首地址。有很多种实现分离式空闲列表的方式,主要区别在于如何定义大小类、何时进行合并、何时向操作系统申请额外的堆内存、是否允许分割等等。下面将介绍几种常见的方式。
5.1 简单分离存储
此方法比较简单粗暴,每个空闲列表中的块大小都是一样的,都是此类列表能容纳的最大值。比如{17 ~ 32}类,这对应的空闲链表中的块大小都是32。
分配与释放的策略是:不分割,不合并。
- 申请堆内存时:记申请的内存块为
M。不论M为何值,每次都申请相同大小的内存片(通常是页大小的整数倍)。然后把这个内存片分为多个大小为M的内存块,组成M对应的空闲列表。 - 分配空闲块时:直接取对应空闲列表的首个空闲块,并分配整个空闲块,不管有没有碎片都不分割。
- 释放已分配块时:不合并,整个块直接放到对应的空闲列表首部。
5.1.1 内存块的结构
对于已分配块而言,由于每次申请的内存片大小都是固定的,所以只需要记录每次向操作系统申请的内存片对应的空闲列表中的块大小,就能通过已分配块的地址推断出它的大小。因此,已分配块就不需要记录大小了,同时又因为释放内存块时没有合并操作,故不需要记录内存块是否已分配。所以,已分配块就不需要头部与脚部了。
对于空闲块,其所处的空闲列表已经暗示了它的大小,再加上不合并,所以空闲块也不需要头部与脚部了。至于如何形成空闲链表,由于不需要合并,那么对空闲链表的操作都是在其首部完成,因而单向链表就能满足需求。所以空闲块只需要存储一个succ指针来记录其下一个空闲块的地址。
5.2 分离适配
每个大小类中的空闲块大小都不固定,释放空闲块时要进行合并,申请空闲块时可以分割掉多余的部分。
- 申请堆内存时:向操作系统申请内存块,将剩余部分(可能没有)放入对应的空闲列表。
- 分配空闲块时:先在对应的空闲列表中搜索,要是找不到大小匹配的块,则到下一级的空闲列表中搜。找到后可选地分割掉多余的部分,把多余部分放入对应的空闲列表。
- 释放已分配块时:合并相邻的空闲块,将新生成的块放入对应的空闲列表。
内存结构与显式空闲列表相同。都需要首尾块标记大小与分配状态,另外空闲块还需要记录前后两个空闲块的地址以组成双向链表。
5.3 伙伴系统

(完)