
(数据在SSTable中是按key排好序的。)
SSTable(Sorted Strings Table) 主要分为以下几个部分:
- DataBlock:存key-value数据
- FilterBlock(可选):存Filter相关数据,例如布隆过滤器
- MetaIndexBlock:存 Filter 的类型,及其在整个文件中的 offset
- IndexBlock:存各个DataBlock在整个文件中的 offset
- Footer:存 MetaIndexBlock 和 IndexBlock 在整个文件中的 offset
除了Footer以外,各种Block的末尾都会有压缩类型(1byte)和CRC校验(4byte)。
| Block | Compression Type |
|---|---|
| DataBlock | SnappyCompression |
| FilterBlock | NoCompression |
| MetaIndexBlock | SnappyCompression |
| IndexBlock | SnappyCompression |
DataBlock
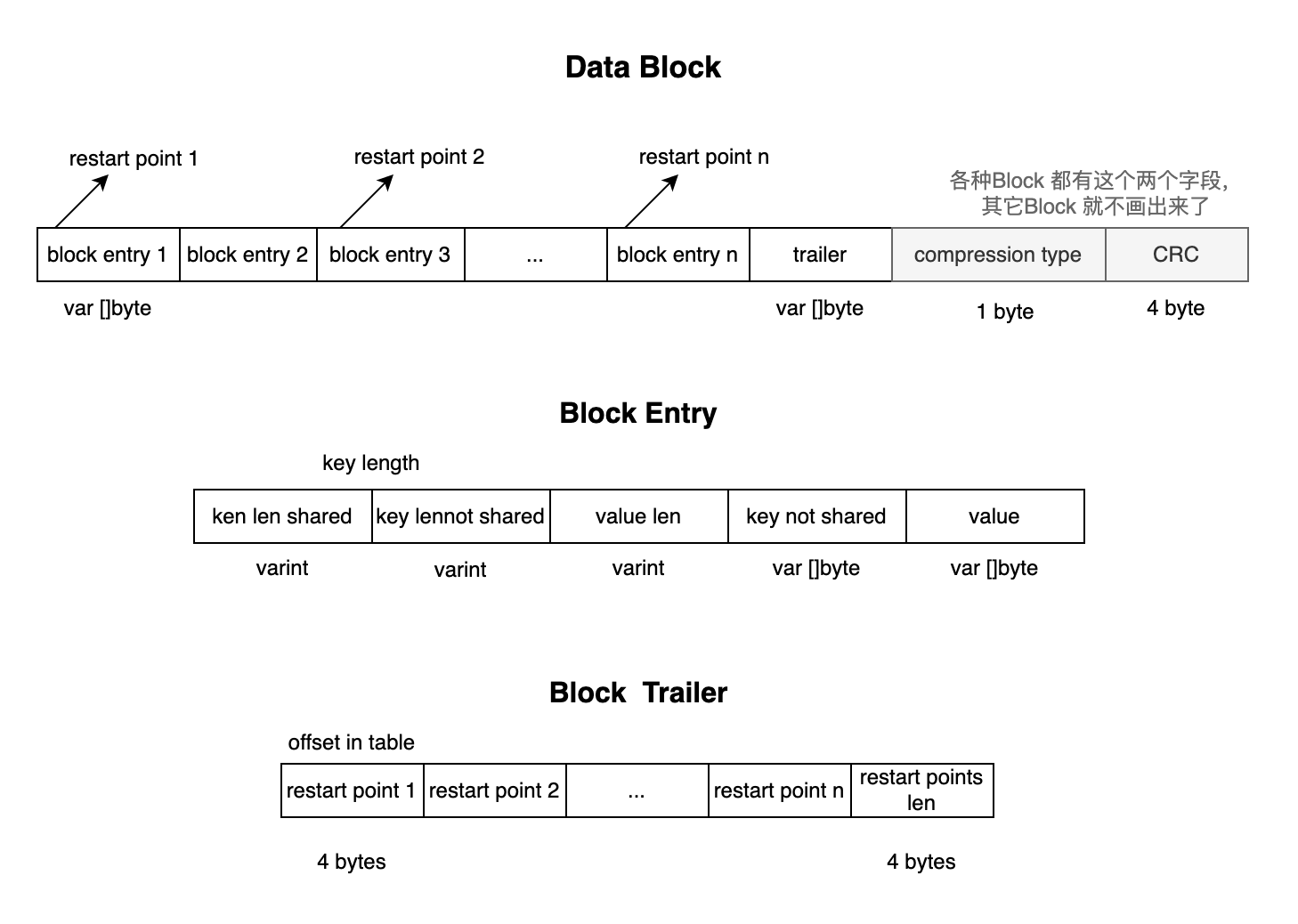
每个 DataBlock 由多个 Entry组成,一个 Entry 就相当于一个 Key-Value pair。但是与 MemDB 不同,key 并不是完整存储,而是分为 shared key 和 not shared key 两个部分。比如对 /service/aaa、/service/bbb这两个key而言, shared key指的就是公共前缀/service/,not shared key 指的就是非公共前缀的部分。为啥要提取公共前缀呢?因为在 SSTable 中的 key都是有序的,因此提取公共前缀可以节省很多存储空间。
当数据量比较大的情况下,可能就没有公共前缀了,那这样的空间节省率并不高。因此每隔16个 Entry就会重新开始计算前缀,每个重新计算的key被称为restart point,作为计算前缀的基准。这些restart point在SSTable中的 offset会被单独记录在 Block Trailer中。另外,这些 restart point 也可以通过二分查找来加快检索指定的key。
因此每个Block Entry 中用两个字段分别存储了 shared key和not shared key 两个部分的长度,然后只存储了not shared key 部分的key,前缀部分的key通过其对应的restart point以及shared key len可以读取到。
MetaIndexBlock 和 IndexBlock 在物理上的结构和 DataBlock 相同,以 key-value的形式存储数据,都有一个或多个 Data Entry 以及 trailer,compression type 和 CRC。二者的图中只是画出了 key-value 在逻辑上表示的数据内容
FilterBlock
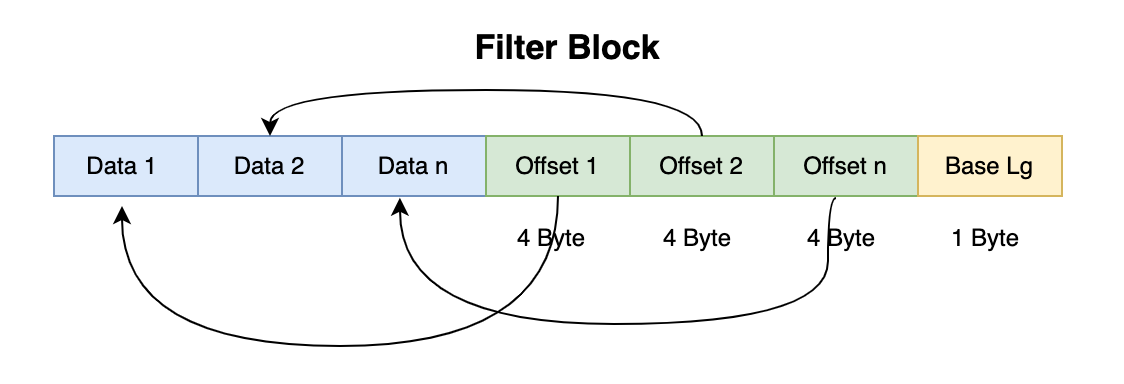
FilterBlock 是用来写入过滤器相关的数据的,默认用的是布隆过滤器。每隔 2BaseLg个字节,就会写一个Filter Data块,每个Filter Data块又会有一个对应的Filter Index记录了其在文件中的Offset。
MetaIndexBlock
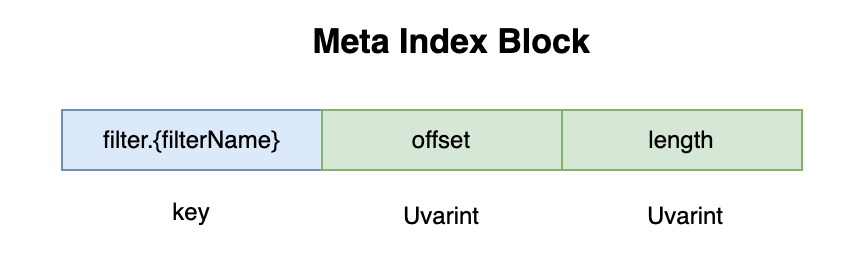
MetaIndexBlock 比较简单,只是存储了 FilterBlock 所使用的过滤器的类型,以及 FilterBlock 在文件中的 offset 和长度。
IndexBlock
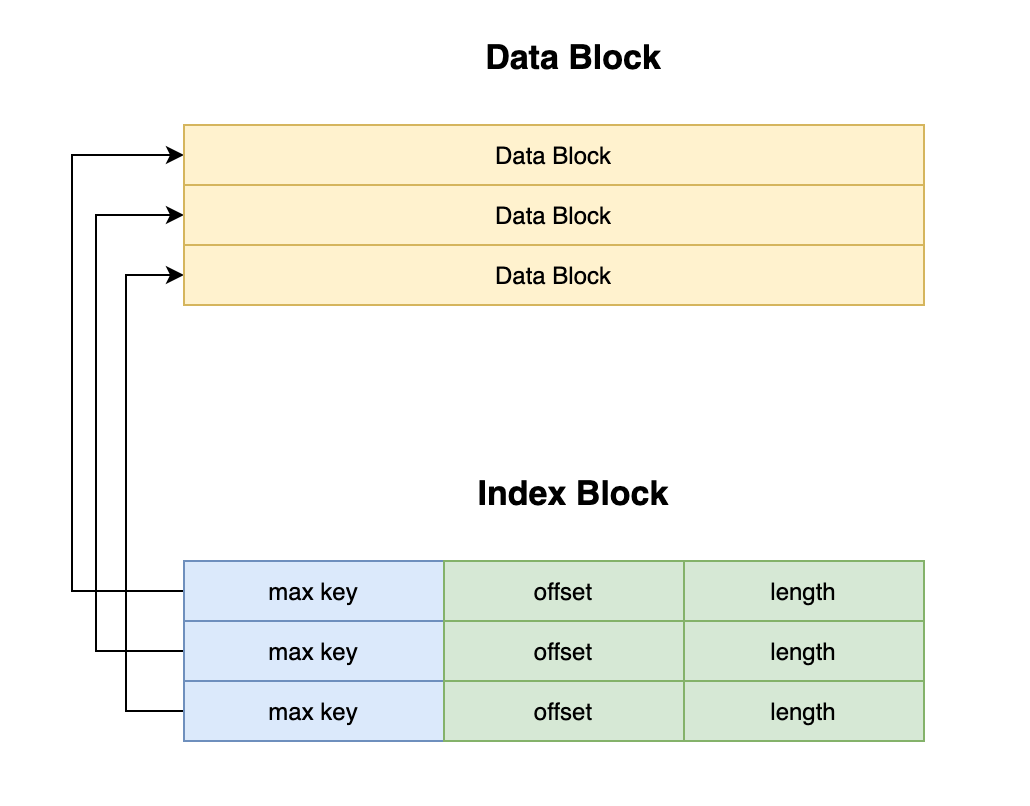
IndexBlock 存储的是 DataBlock 的索引,每个 DataBlock 有 3个字段来存储相关信息,分别是:
- max key: 这个Block中存储的最大的 key,以便于用二分查找来定位key在哪个block
- offset: 这个Block在文件中的 offset
- length: 这个Block一共多少字节(如果有压缩,就是压缩后的)
Footer
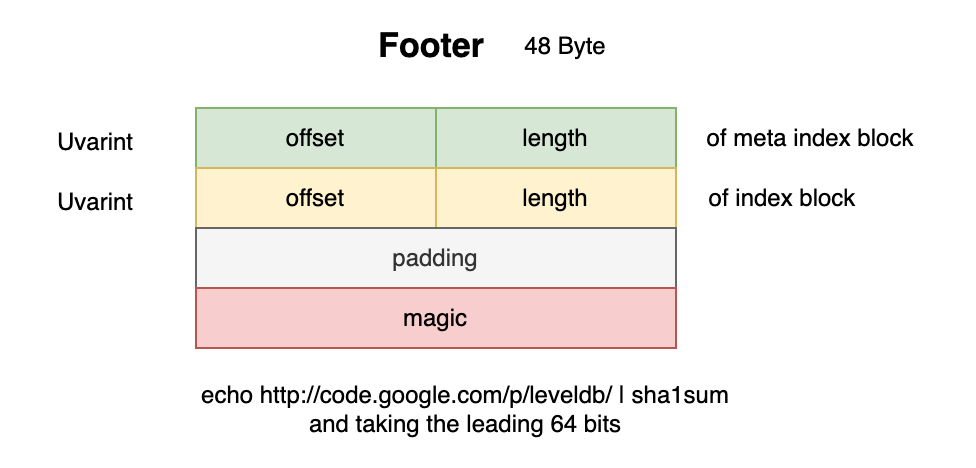
Footer 用来存储 MetaIndexBlock 和 IndexBlock 在文件中的 offset 和 大小。固定占 48 字节。最后一个字段是 Magic 字段。
(完)
References: