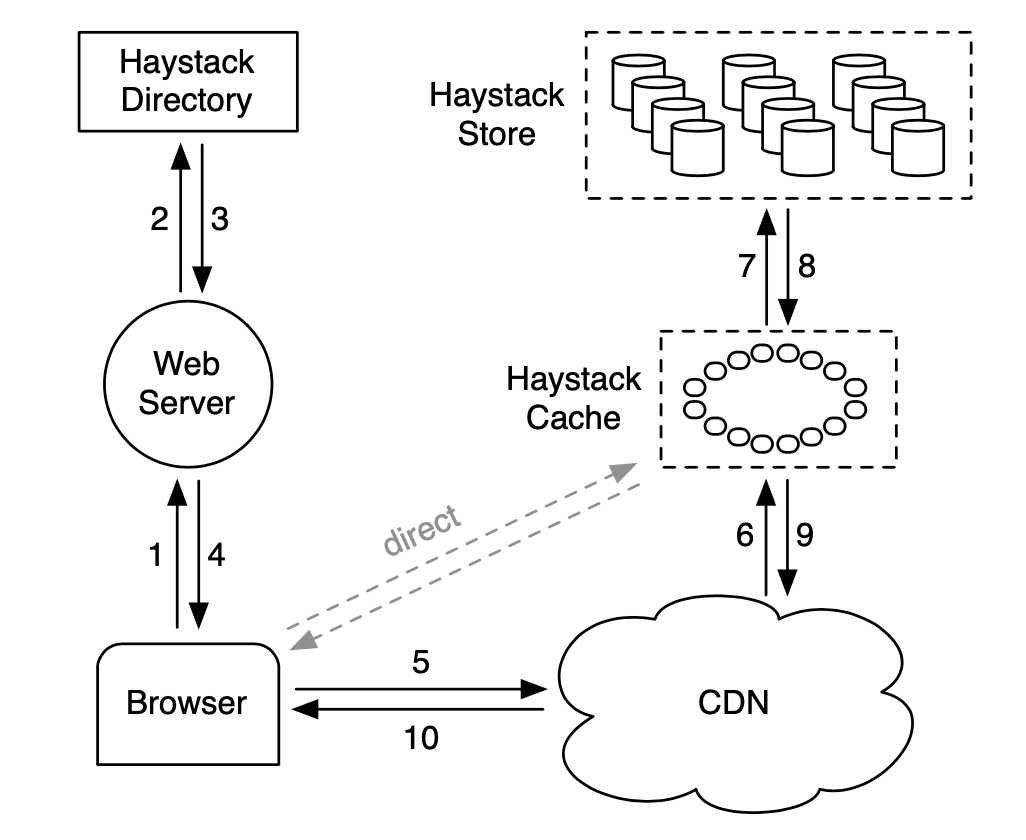
假如你维护着一个社交媒体公司的图片服务,每天都会有几十亿张照片、缩略图需要存储,还需要快速响应对所有历史照片的随机查询请求,那么你会怎么进行系统设计呢?
需要解决的核心问题有:
- 怎么存放海量的图片,因为单机可能放不下
- 怎么节约磁盘空间,因为会有很多小文件,比如缩略图什么的
- 怎么快速响应查询请求,比如查询1年前上传的图片
- (可靠性不在本文的讨论访问内)
分布式存储
我们可以用多台服务器组成一个分布式系统来存放大量的图片文件,只需要有一台或多台 metaserver 来记录每个文件存放在哪台机器上及其具体路径。
合并文件内容
文件系统存放数据的最小单元是 Block,而不是 Byte。一般一个 Block 大小是 4KB。如果图片比较小的话,比如只有1KB,那么它实际占用的存储空间会是 4KB,有3KB的空间就被浪费掉了。
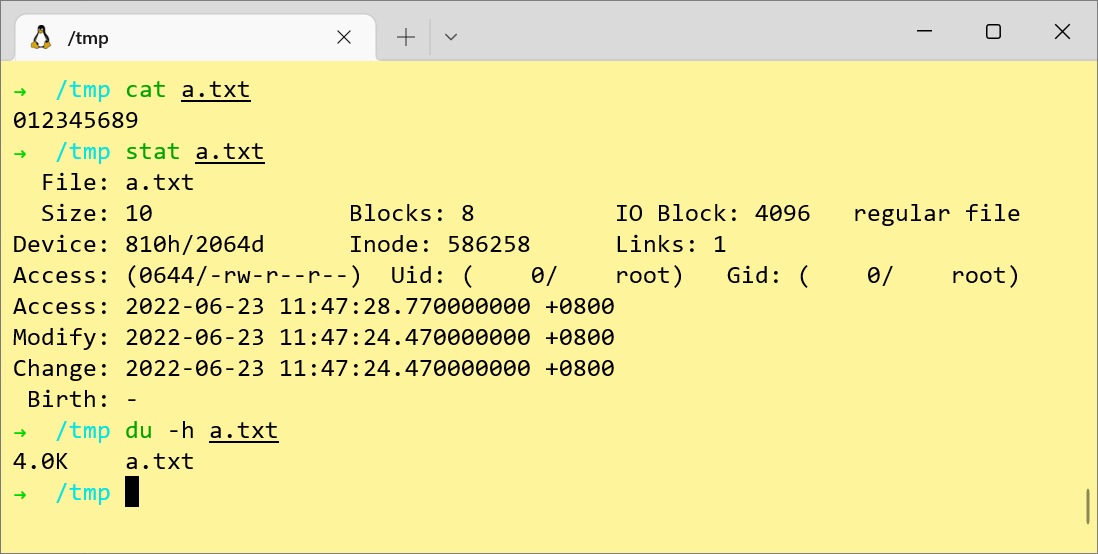
比如上图中的 a.txt文件内容实际上只有 10 Byte,但是仍然会占用 4KB的空间。当有上亿个这样的小文件存在时,就会有大量的存储资源被浪费。因此,我们可以考虑将多个文件合并存放到一个大文件中,尽量避免产生浪费。然后再单独地维护一份元信息,记录每个小文件存储在哪个大文件中,及其offset。
内存化inode
对于最近刚上传的图片,我们可以通过缓存来加速访问,但是对于创建时间比较久的,就需要去“摸盘”了。在ext4文件系统上,要读取一个文件的内容,一般需要以下几个步骤:
- 找到父文件夹的
inode - 找到该文件的
inode - 通过
inode中记录的block地址,找到并读取文件内容
以上过程一般至少产生3次I/O,单独读取一个文件的耗时还可以接受,但是当请求次数一上来,找到文件的数据在哪个block 这个过程就是整个系统的瓶颈了。
为了尽量少地产生I/O,我们可以抛开操作系统内置文件系统,自己来维护类似的inode。这样既可以减少 I/O,还可以在内存中进行缓存,加快访问速度。
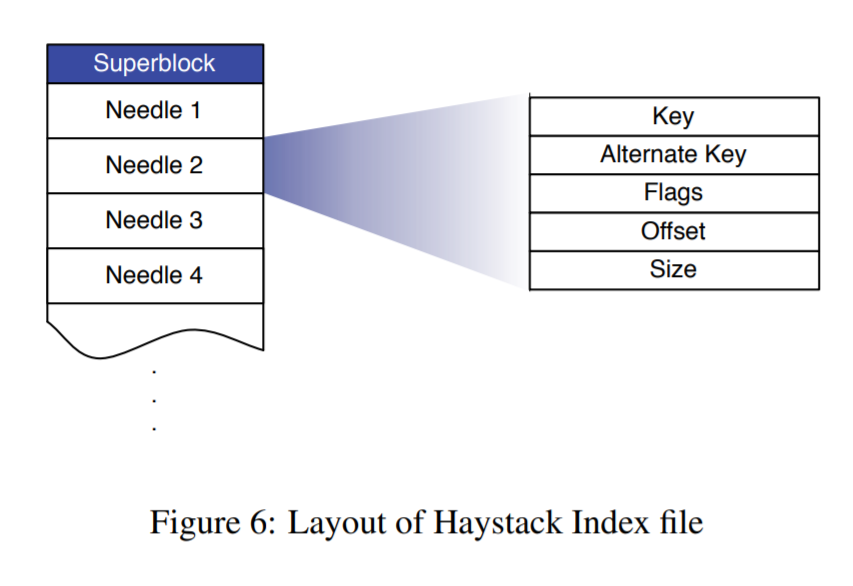
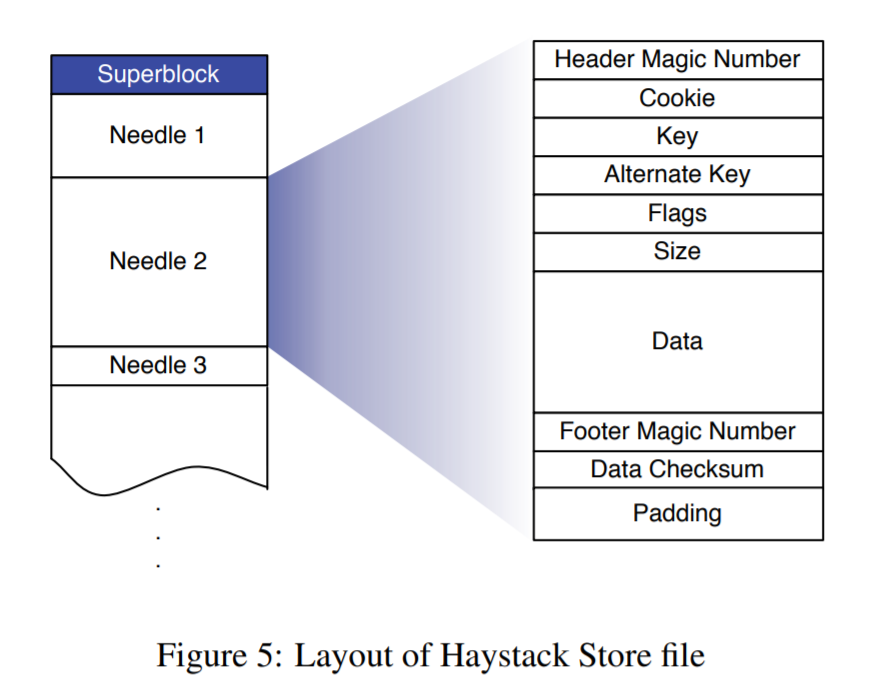
Haystack Store
综上,我们可以引出 Haystack Store 的具体实现。Haystack Store 分为3个部分:
- 内存Cache,包括了每个小文件的元信息
- 数据文件,包括了多个小文件的数据
- 索引文件,包括了每个小文件的元信息
创建文件
创建新文件分为3步:
- 同步写文件内容:在大文件末尾追加文件数据
- 同步更新内存中的 mapping 信息
- 异步写索引文件
如果文件已经存在了,则不会去覆盖或者删除旧数据,而是直接追加新数据,然后更新 mapping 信息,让旧数据访问不到即可。
索引文件主要是为了在服务重启后,加速内存中的 mapping 关系的建立。
删除文件
删除文件时,同时同步地将内存中的 flag 和数据文件中的 flag 更新为已删除。
查询文件
查询文件比较快速,直接读取内存中的 mapping 信息,定位到数据存放在哪个大文件中,先看下文件是否已经删除了,如果没有,则直接根据offset进行数据读取。
Compaction
当有大量文件被删除或更新时,需要把它们占用的磁盘空间释放掉,因此有一个后台任务去干这个事情。
这篇写得真烂,-_-||
Ref: