1.实验环境
- OS: Ubuntu Kylin 15.10
- IDE: JetBrains Pycharm 4.5.4
- Programming Language: Python 2.7
- GUI Library: PyQt5(Qt5.4.2)
2.实验方案设计
2.1 程序结构
- tokens.py: 词法单元
- lexer.py: 词法分析器
- parser.py: 语法分析器
- nodes.py: 语法树节点
2.2 分析方法
语法分析其实就是按照事先定义好的语法,对词法分析器返回的Token与语法元素进行匹配,若是发现不匹配则报错。本程序采用递归下降语法分析器进行分析。
2.3 何为递归?
像JavaCC的源程序一样,我们为每个非终结符定义一个处理函数。当在处理函数中遇到另一个非终结符时,我们便调用该非终结符的处理函数进行处理。以此递归地处理下去,直到某个处理函数中没有非终结符。
例如,定义while循环语句的语法如下:
whileStmt ::= "while" "(" condition ")" "{" statements "}"
condition ::= expression compOp expression
其中condition,statements是非终结符。
假设各个非终结符的FIRST集合交集为空,当我们遇到while时,便可以判断这是while循环的一部分。那么我们有理由期待接下来的一个Token为(。然后,我们进入到condition的处理函数。当然,condition中又会遇到非终结符expression,compOp等,会触发一连串的处理函数的调用。此之谓递归
2.4 何为下降?
在语法分析的过程中,我们会构建一个抽象语法树。每个非终结符相当于语法树中的一个节点,产生式的左部相当于父节点;产生式的右部中的非终结符相当于子节点,同时他们互为兄弟节点。
递归的过程就像是构建语法树的过程。起先,只有一个在上面的根节点,当每个处理函数返回后都会在语法树中添入一个子节点。随着递归的进行,语法树不断地向下延伸。当语法树不再生长时,语法分析也就结束了。
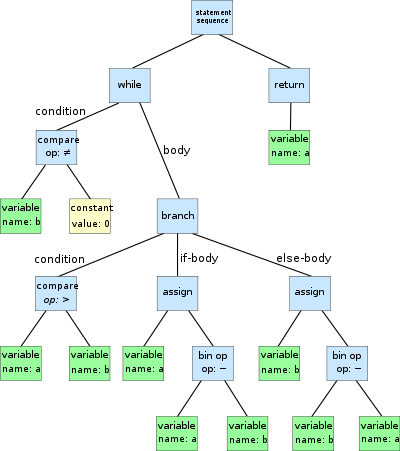
例如有如下的程序:
while (b ≠ 0){
if (a > b)
a = a − b;
else
b = b − a;
return a;
}
其抽象语法树为
2.5 如何与语法进行匹配?
那么该如何与预定义的语法进行匹配呢?这就要用到FIRST集合与FOLLOW集合了。其实也并没有辣么理论化,只需要根据当前读取到的Token判断应该进入哪个处理函数就行了。比如读到while就知道要进入while的处理函数;读到if就知道要处理if了。
进入处理函数之后,我们定义一个expect(Token)函数来期待接下来的Token。传入期待的Token,要是与接下来读取到的Token匹配,就继续往下分析,要是不匹配,就抛出异常,停止分析。
可以参考https://en.wikipedia.org/wiki/Recursive_descent_parser中的C语言实现。
当然,也需要一个缓冲区来存放“脏Token”。因为有写产生式中存在可省略的部分。比如if-else结构中的else可以省略,我们需要向前读一个Token来判断是否进入else部分。这时候就需要和词法分析一样,保存可能读到的脏Token了。
3. 语法树构建
语法树的构建其实也很简单,只需要每个处理函数返回其分析的非终结符就ok了。
节点类构建如下:
class Node(object):
def __init__(self, lexeme, parent=None):
self.lexeme = lexeme
self.parent = parent
self.childItems = []
def __str__(self):
return self.lexeme
def append(self, item):
"""
Append a item as its child.Show as a sub row in treeView
:param item:
"""
item.parent = self
self.childItems.append(item)
def pop(self):
self.childItems.pop()
while的处理函数:
def _parse_stmt_while(self):
"""
whileStmt ::=
<WHILE> <LPAREN> condition <RPAREN> <LBRACE> statements <RBRACE>
:return:
"""
self._expect(Token_WHILE)
self._expect(Token_LPAREN)
cond = self._parse_cond()
self._expect(Token_RPAREN)
self._expect(Token_LBRACE)
stmts = self._parse_stmts()
self._expect(Token_RBRACE)
return WhileStmtNode(cond, stmts)
whileStmtNode的具体实现
class WhileStmtNode(Node):
def __init__(self, cond, stmts):
super(WhileStmtNode, self).__init__('WhileStmt')
self.append(cond)
self.append(stmts)
其他非终结符的处理大同小异。详见https://github.com/jun-kai-xin/cinter
3.2 语法树输出
语法树构建完成后,需要将其输出看看效果。此时,从上到下利用深度优先遍历算法输出即可。
在Node类中添加如下方法,然后对根节点调用之即可
def gen(self):
stack = [self]
stdout = StringIO.StringIO()
while len(stack) > 0:
n = stack.pop()
p = n.parent
indent = []
while p:
if p.parent and p.indexInParent() < p.parent.childCount() - 1:
indent.append('| ')
else:
indent.append(' ')
p = p.parent
indent.reverse()
stdout.write(''.join(indent))
stdout.write('|----> %s\n' % str(n))
l = list(n.childItems)
l.reverse()
stack += l
return stdout.getvalue()
4. 测试
程序
//This is a test for arithmetic
int a;
real b;
b=3.14159265354+2.718281828459045;
a=((a+2)*6-(b/2048+3))/9*(9+0-b);
抽象语法树
|----> Stmts
|----> DeclareStmt
| |----> INT : "int"
| |----> ID : "a"
|----> DeclareStmt
| |----> REAL : "real"
| |----> ID : "b"
|----> AssignStmt
| |----> ID : "b"
| |----> Expression
| |----> Term
| | |----> Factor
| | |----> REAL_LITERAL : "3.14159265354"
| |----> Add
| | |----> PLUS : "+"
| |----> Term
| |----> Factor
| |----> REAL_LITERAL : "2.71828182846"
|----> AssignStmt
|----> ID : "a"
|----> Expression
|----> Term
|----> Factor
| |----> Expression
| |----> Term
| | |----> Factor
| | | |----> Expression
| | | |----> Term
| | | | |----> Factor
| | | | |----> ID : "a"
| | | |----> Add
| | | | |----> PLUS : "+"
| | | |----> Term
| | | |----> Factor
| | | |----> INT_LITERAL : "2"
| | |----> Multiply
| | | |----> TIMES : "*"
| | |----> Factor
| | |----> INT_LITERAL : "6"
| |----> Add
| | |----> MINUS : "-"
| |----> Term
| |----> Factor
| |----> Expression
| |----> Term
| | |----> Factor
| | | |----> ID : "b"
| | |----> Multiply
| | | |----> DIVIDE : "/"
| | |----> Factor
| | |----> INT_LITERAL : "2048"
| |----> Add
| | |----> PLUS : "+"
| |----> Term
| |----> Factor
| |----> INT_LITERAL : "3"
|----> Multiply
| |----> DIVIDE : "/"
|----> Factor
| |----> INT_LITERAL : "9"
|----> Multiply
| |----> TIMES : "*"
|----> Factor
|----> Expression
|----> Term
| |----> Factor
| |----> INT_LITERAL : "9"
|----> Add
| |----> PLUS : "+"
|----> Term
| |----> Factor
| |----> INT_LITERAL : "0"
|----> Add
| |----> MINUS : "-"
|----> Term
|----> Factor
|----> ID : "b"