1. Redis
1.1 场景1:消息会丢失
最简单的消息队列
producer.lpush(queue, message)
consumer.rpop(queue)
异常情况:consumer取出message之后,consumer宕机了
若宕机时message没有被处理,则该message就丢失了
1.2 场景2:确保消息不丢失
为了保证消息不丢失,可以增加一个待处理队列,从任务队列取出任务之后,先将其加入到待处理队列中;待任务成功执行,再将其从待处理队列中删除。
producer.lpush(queue_wait, message)
# use a processing queue
consumer.rpoplpush(queue_process, message)
# after processing
consumer.lrem(queue_process, 1, message)
如果只有一个consumer,可以在其宕机重启时将queue_process中的messages取出并添加到queue_wait中
messages = consumer.lrange(queue_process, 0, -1)
consumer.rpush(queue_wait, *messages)
如果有多个consumers,则需要给每个message设置一个超时时间,周期性地启动一个monitor来检察出queue_process中的超时message,并将其取出,重新放入queue_process。
messages = monitor.lrange(queue_process, 0, -1)
for message in messages:
if expired(message):
monitor.rpush(queue_wait, message)
缺点:需要额外记录message的加入时间,且无法保证message的时效性。
异常情况:由于redis是基于内存的,消息激增导致内存不足或宿主机宕机都会使服务不可用
1.3 Disque
2. Zookeeper
2.1 创建一个节点
创建一个节点,消息将会存到其子节点中
/**
* Constructor of producer-consumer queue
*
* @param address
* @param name
*/
Queue(String address, String name) {
super(address);
this.root = name;
// Create ZK node name
if (zk != null) {
try {
Stat s = zk.exists(root, false);
if (s == null) {
zk.create(root, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
} catch (KeeperException e) {
System.out
.println("Keeper exception when instantiating queue: "
+ e.toString());
} catch (InterruptedException e) {
System.out.println("Interrupted exception");
}
}
}
2.2 produce
发送消息时,在父节点下创建类型为PERSISTENT_SEQUENTIAL的连续的子节点
/**
* Add element to the queue.
*
* @param i
* @return
*/
boolean produce(int i) throws KeeperException, InterruptedException{
ByteBuffer b = ByteBuffer.allocate(4);
byte[] value;
// Add child with value i
b.putInt(i);
value = b.array();
zk.create(root + "/element", value, Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL);
return true;
}
2.3 consume
/**
* Remove first element from the queue.
*
* @return
* @throws KeeperException
* @throws InterruptedException
*/
int consume() throws KeeperException, InterruptedException{
int retvalue = -1;
Stat stat = null;
// Get the first element available
while (true) {
synchronized (mutex) {
List<String> list = zk.getChildren(root, true);
if (list.size() == 0) {
System.out.println("Going to wait");
mutex.wait();
} else {
Integer min = new Integer(list.get(0).substring(7));
for(String s : list){
Integer tempValue = new Integer(s.substring(7));
//System.out.println("Temporary value: " + tempValue);
if(tempValue < min) min = tempValue;
}
System.out.println("Temporary value: " + root + "/element" + min);
byte[] b = zk.getData(root + "/element" + min,
false, stat);
zk.delete(root + "/element" + min, 0);
ByteBuffer buffer = ByteBuffer.wrap(b);
retvalue = buffer.getInt();
return retvalue;
}
}
}
}
3. RabbitMQ
3.1 应用场景
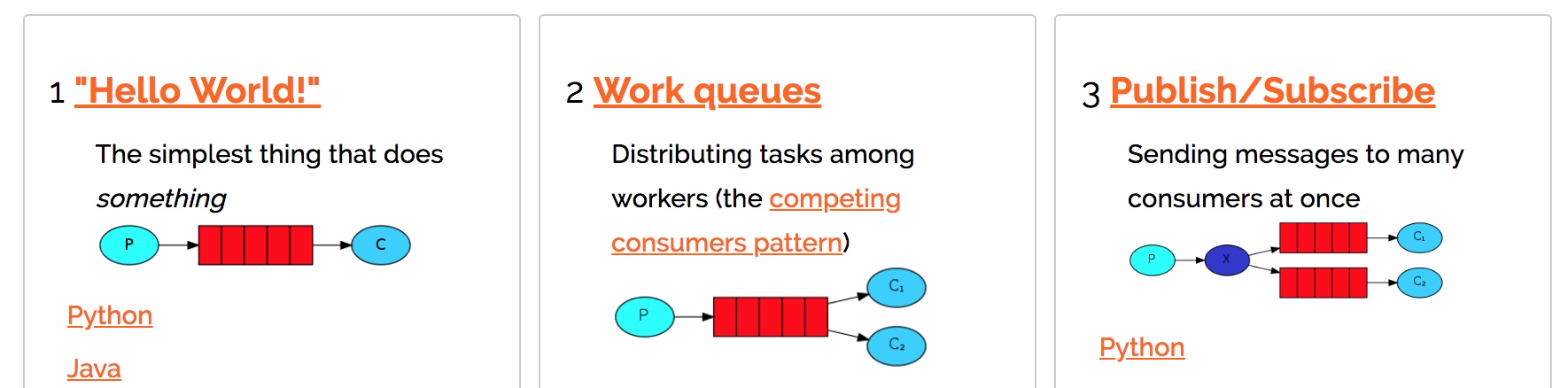
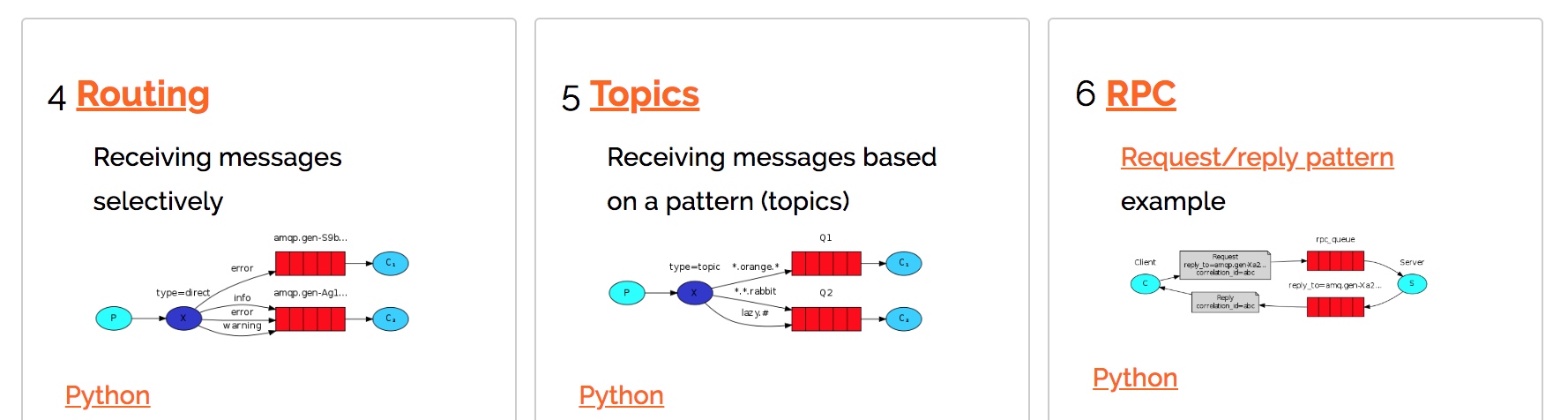
3.2 特点
- Message acknowledgment
consumer收到消息处理完成后可以发送ACK
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback, queue='hello')
- Message durability
channel.queue_declare(queue='hello', durable=True)
see Consumer Acknowledgements and Publisher Confirms
4. Kafka
4.1 基本概念
- Broker 消息队列中常用的概念,在Kafka中指部署了Kafka实例的服务器节点。
- Topic 用来区分不同类型信息的主题。比如应用程序A订阅了主题t1,应用程序B订阅了主题t2而没有订阅t1,那么发送到主题t1中的数据将只能被应用程序A读到,而不会被应用程序B读到。
- Partition 每个topic可以有一个或多个partition(分区)。分区是在物理层面上的,不同的分区对应着不同的数据文件。Kafka使用分区支持物理上的并发写入和读取,从而大大提高了吞吐量。
- Record 实际写入Kafka中并可以被读取的消息记录。每个record包含了key、value和timestamp。
- Producer 生产者,用来向Kafka中发送数据(record)。
- Consumer 消费者,用来读取Kafka中的数据(record)。
- Consumer Group 一个消费者组可以包含一个或多个消费者。使用多分区+多消费者方式可以极大提高数据下游的处理速度。
4.2 基本原理
4.2.1 Topic和数据日志
主题是同一类别的消息记录(record)的集合。在Kafka中,一个主题通常有多个订阅者。对于每个主题,Kafka集群维护了一个分区数据日志文件结构如下:
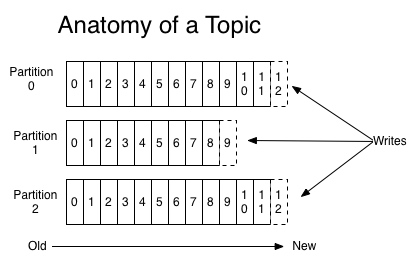
每个partition都是一个有序并且不可变的消息记录集合。当新的数据写入时,就被追加到partition的末尾。在每个partition中,每条消息都会被分配一个顺序的唯一标识,这个标识被称为offset,即偏移量。注意,Kafka只保证在同一个partition内部消息是有序的,在不同partition之间,并不能保证消息有序。
Kafka可以配置一个保留期限,用来标识日志会在Kafka集群内保留多长时间。Kafka集群会保留在保留期限内所有被发布的消息,不管这些消息是否被消费过。比如保留期限设置为两天,那么数据被发布到Kafka集群的两天以内,所有的这些数据都可以被消费。当超过两天,这些数据将会被清空,以便为后续的数据腾出空间。由于Kafka会将数据进行持久化存储(即写入到硬盘上),所以保留的数据大小可以设置为一个比较大的值。
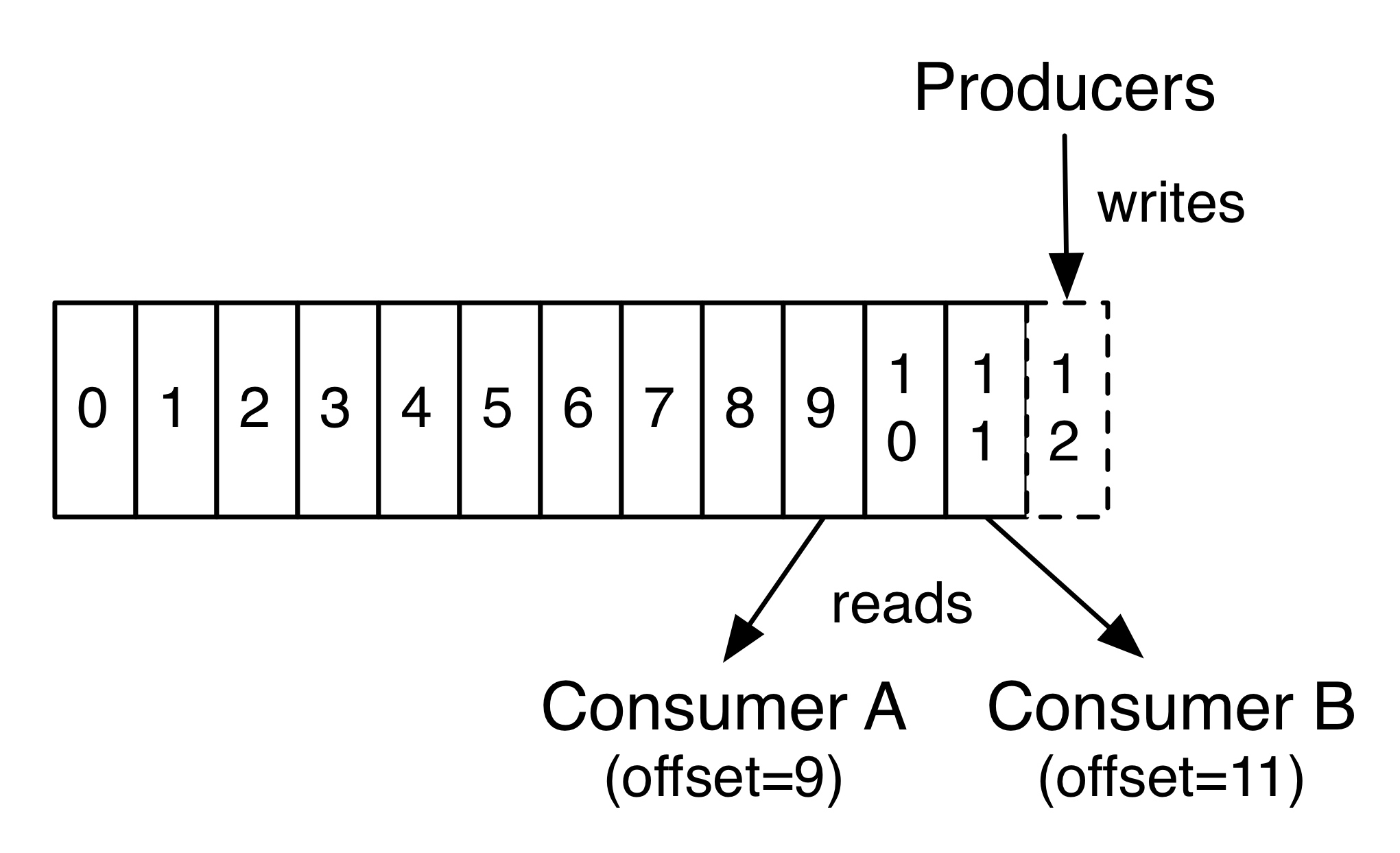
事实上,在单个消费者层面上,每个消费者保存的唯一的元数据就是它所消费的数据日志文件的偏移量。偏移量是由消费者来控制的,通常情况下,消费者会在读取记录时线性的提高其偏移量。不过由于偏移量是由消费者控制,所以消费者可以将偏移量设置到任何位置,比如设置到以前的位置对数据进行重复消费,或者设置到最新位置来跳过一些数据。
4.2.2 容错
每个topic的分区都可以分布在Kafka集群的不同服务器上。比如topic A有partition 0,1,2,分别分布在Broker 1,2,3上面。每个服务器都可以处理分布在它上面的分区的写入和读取操作。另外,每个分区也可以配置多个副本用来提高容错性。
每个partition有一个服务器充当“leader”,零至多个服务器充当“follower”。Leader会处理针对于这个分区的所有读写操作,而follower只是被动的从leader中复制数据。当leader挂掉了,那么原有的follower会自动选举出一个新的leader。每台服务器都会作为一些分区的leader,也会作为其他分区的follower,所以Kafka集群内的负载会比较均衡。
4.2.3 生产者
生产者可以将数据写入到选定的主题。生产者负责决定要将哪条记录写入到那个分区当中。可以使用轮询方式,即每次取一小段时间的数据写入某个partition,下一小段的时间写入下一个partition;也可以使用一些分区函数(比如哈希),根据record的key值将记录写入不同的分区。
4.2.4 消费者
多个消费者实例可以组成一个消费者组,并用一个标签来标识这个消费者组。一个消费者组中的不同消费者实例可以运行在不同的进程甚至不同的服务器上。
如果所有的消费者实例都在同一个消费者组中,那么消息记录会被很好的均衡的发送到每个消费者实例。
如果所有的消费者实例都在不同的消费者组,那么每一条消息记录会被广播到每一个消费者实例。
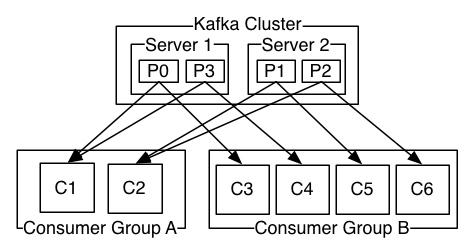
举个例子。如上图所示,一个两个节点的Kafka集群上拥有一个四个partition(P0-P3)的topic。有两个消费者组都在消费这个topic中的数据,消费者组A有两个消费者实例,消费者组B有四个消费者实例。 从图中我们可以看到,在同一个消费者组中,每个消费者实例可以消费多个分区,但是每个分区最多只能被消费者组中的一个实例消费。也就是说,如果有一个4个分区的主题,那么消费者组中最多只能有4个消费者实例去消费,多出来的都不会被分配到分区。其实这也很好理解,如果允许两个消费者实例同时消费同一个分区,那么就无法记录这个分区被这个消费者组消费的offset了。如果在消费者组中动态的上线或下线消费者,那么Kafka集群会自动调整分区与消费者实例间的对应关系。